Publications
2025
- Conditional Gradient Methods: From Core Principles to AI ApplicationsGábor Braun, Alejandro Carderera, Cyrille W. Combettes, Hamed Hassani, Amin Karbasi, Aryan Mokhtari, and Sebastian Pokutta2025
The purpose of this survey is to serve both as a gentle introduction and a coherent overview of state-of-the-art Frank-Wolfe algorithms, also called conditional gradient algorithms, for function minimization. These algorithms are especially useful in convex optimization when linear optimization is cheaper than projections.
@book{braun2025conditional, title = {Conditional Gradient Methods: From Core Principles to AI Applications}, author = {Braun, G{\'a}bor and Carderera, Alejandro and Combettes, Cyrille W. and Hassani, Hamed and Karbasi, Amin and Mokhtari, Aryan and Pokutta, Sebastian}, publisher = {Society for Industrial and Applied Mathematics (SIAM)}, year = {2025}, doi = {10.1137/1.9781611978568}, }

2022
- FrankWolfe.jl: A High-Performance and Flexible Toolbox for Frank-Wolfe Algorithms and Conditional GradientsMathieu Besançon, Alejandro Carderera, and Sebastian PokuttaINFORMS Journal on Computing, 2022
We present FrankWolfe.jl, an open-source implementation of several popular Frank-Wolfe and Conditional Gradients variants for first-order constrained optimization. The package is designed with flexibility and high-performance in mind, allowing for easy extension and relying on few assumptions regarding the user-provided functions. It supports Julia’s unique multiple dispatch feature, and interfaces smoothly with generic linear optimization formulations using MathOptInterface.jl.
@article{besancon2022frankwolfe, title = {FrankWolfe.jl: A High-Performance and Flexible Toolbox for Frank-Wolfe Algorithms and Conditional Gradients}, author = {Besan{\c{c}}on, Mathieu and Carderera, Alejandro and Pokutta, Sebastian}, journal = {INFORMS Journal on Computing}, year = {2022}, }
2021
- CG-INDy: Conditional Gradient-based Identification of Non-linear DynamicsJournal of Computational and Applied Mathematics, 2021
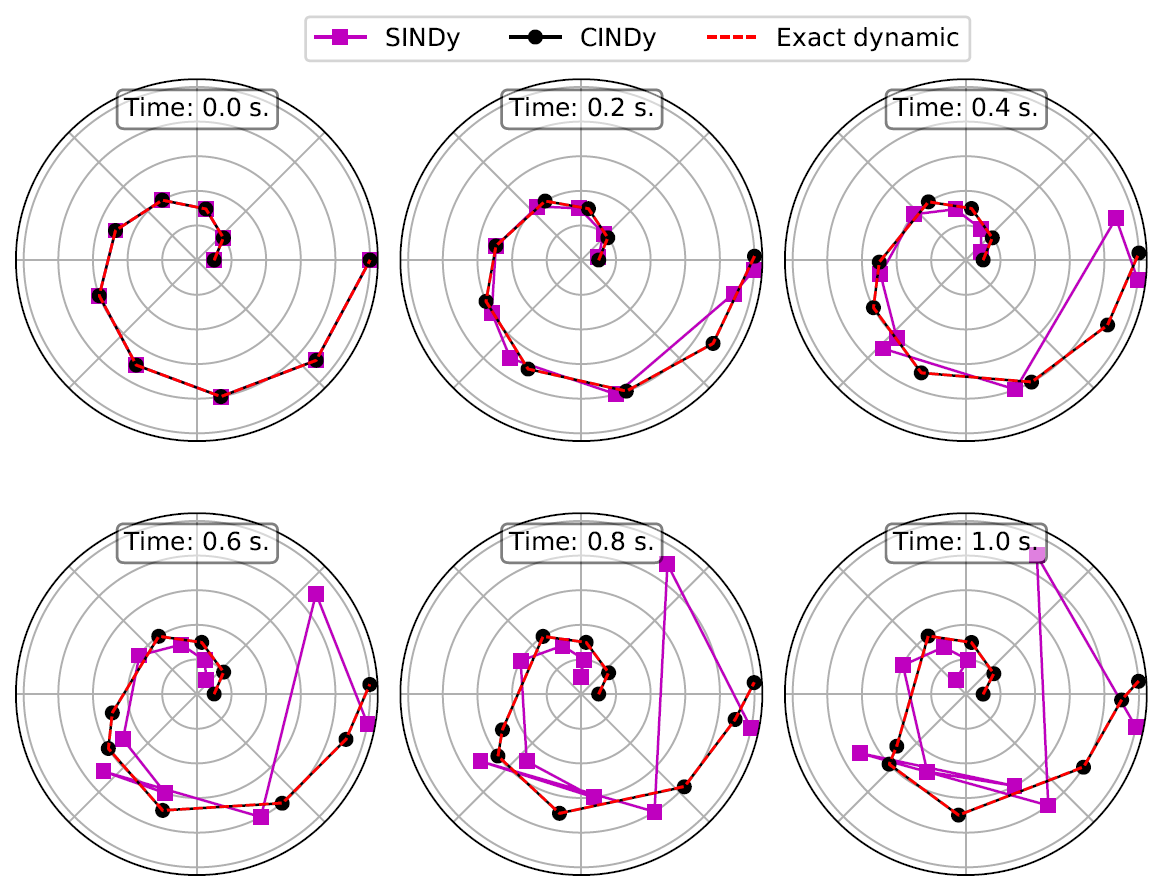
Governing equations are essential to the study of nonlinear dynamics, often enabling the prediction of previously unseen behaviors as well as the inclusion into control strategies. The discovery of governing equations from data thus has the potential to transform data-rich fields where well-established dynamical models remain unknown. This work contributes to the recent trend in data-driven sparse identification of nonlinear dynamics of finding the best sparse fit to observational data in a large library of potential nonlinear models. We propose an efficient first-order Conditional Gradient algorithm for solving the underlying optimization problem. In comparison to the most prominent alternative algorithms, the new algorithm shows significantly improved performance on several essential issues like sparsity-induction, structure-preservation, noise robustness, and sample efficiency.
@article{carderera2021cindy, title = {CG-INDy: Conditional Gradient-based Identification of Non-linear Dynamics}, author = {Carderera, Alejandro and Pokutta, Sebastian and Sch{\"u}tte, Christof and Weiser, Martin}, journal = {Journal of Computational and Applied Mathematics}, year = {2021}, } - Parameter-Free Locally Accelerated Conditional GradientsIn International Conference on Machine Learning (ICML), 2021
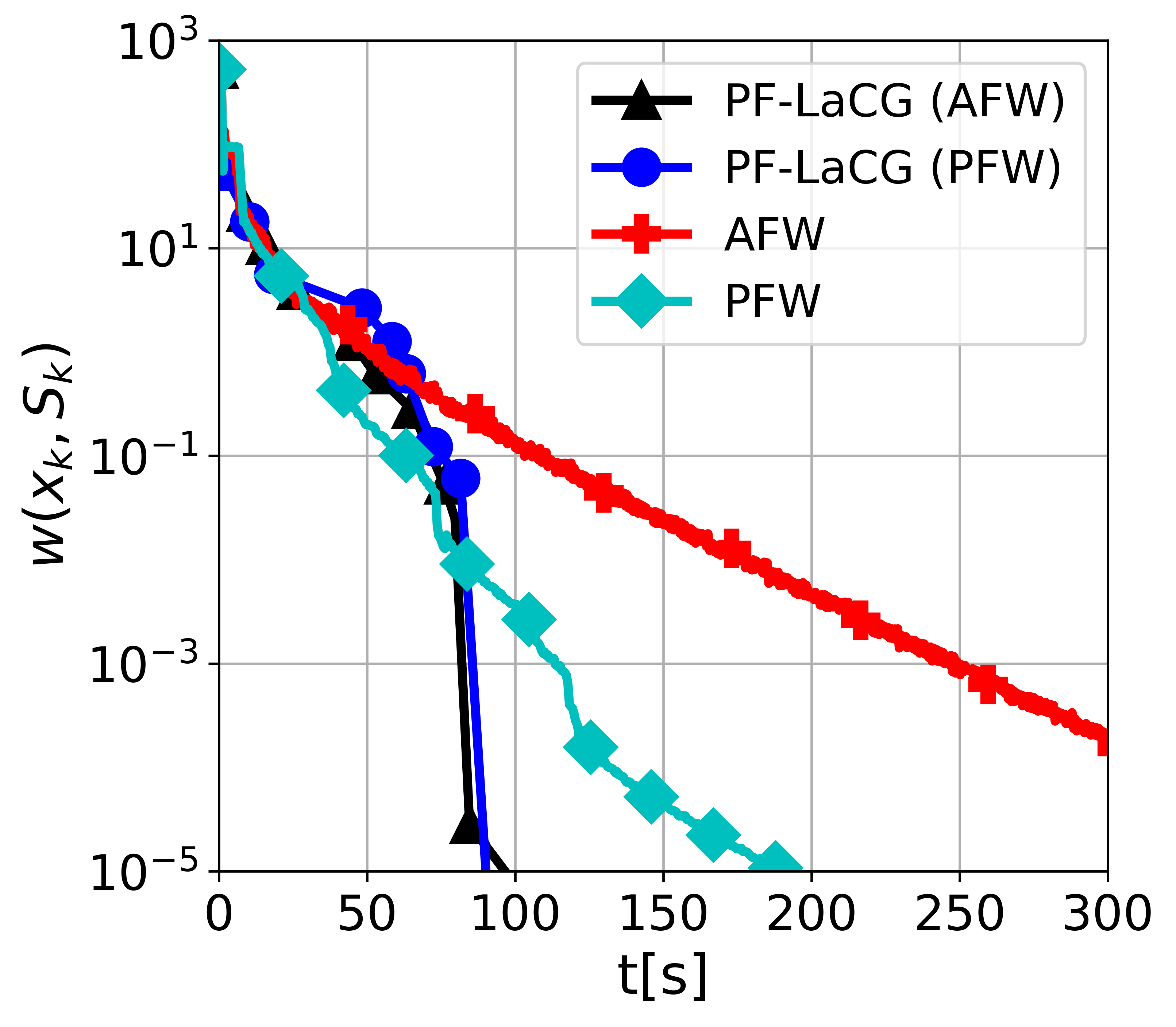
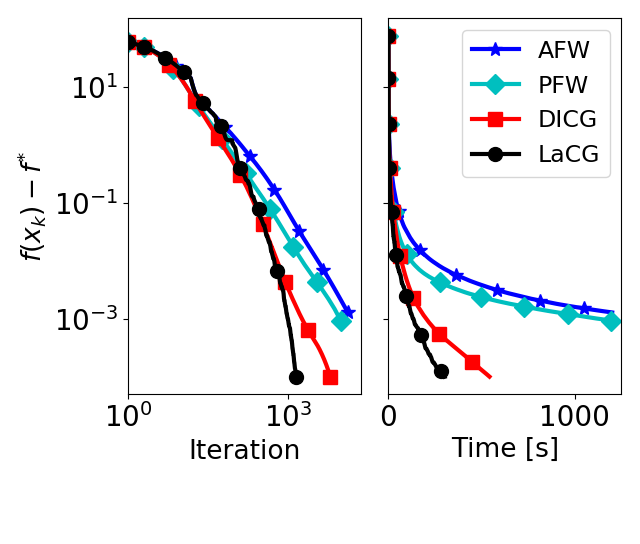
Projection-free conditional gradient (CG) methods are the algorithms of choice for constrained optimization setups in which projections are often computationally prohibitive but linear optimization over the constraint set remains computationally feasible. Unlike in projection-based methods, globally accelerated convergence rates are in general unattainable for CG. However, a very recent work on Locally accelerated CG (LaCG) has demonstrated that local acceleration for CG is possible for many settings of interest. The main downside of LaCG is that it requires knowledge of the smoothness and strong convexity parameters of the objective function. We remove this limitation by introducing a novel, Parameter-Free Locally accelerated CG (PF-LaCG) algorithm, for which we provide rigorous convergence guarantees. Our theoretical results are complemented by numerical experiments, which demonstrate local acceleration and showcase the practical improvements of PF-LaCG over non-accelerated algorithms, both in terms of iteration count and wall-clock time.
@inproceedings{carderera2021pflacg, title = {Parameter-Free Locally Accelerated Conditional Gradients}, author = {Carderera, Alejandro and Diakonikolas, Jelena and Lin, Cheuk Yin and Pokutta, Sebastian}, booktitle = {International Conference on Machine Learning (ICML)}, year = {2021}, } - Simple Steps are all you Need: Frank-Wolfe and Generalized Self-Concordant FunctionsAlejandro Carderera, Mathieu Besançon, and Sebastian PokuttaIn Advances in Neural Information Processing Systems (NeurIPS), 2021
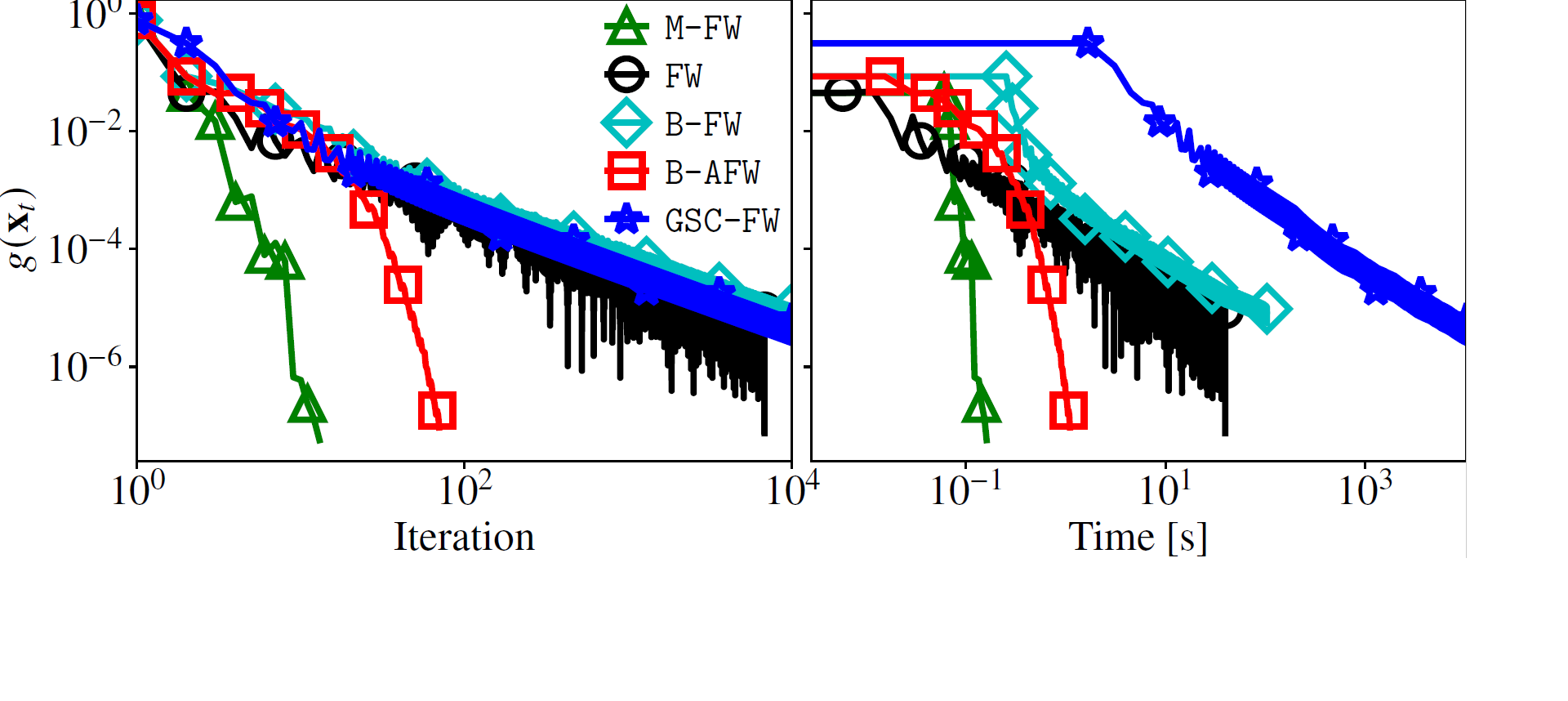
Generalized self-concordance is a key property present in the objective function of many important learning problems. We establish the convergence rate of a simple Frank-Wolfe variant that uses the open-loop step size strategy γt=2/(t+2), obtaining a O(1/t) convergence rate for this class of functions in terms of primal gap and Frank-Wolfe gap, where t is the iteration count. This avoids the use of second-order information or the need to estimate local smoothness parameters of previous work. We also show improved convergence rates for various common cases, e.g., when the feasible region under consideration is uniformly convex or polyhedral.
@inproceedings{carderera2021gsc, title = {Simple Steps are all you Need: Frank-Wolfe and Generalized Self-Concordant Functions}, author = {Carderera, Alejandro and Besan{\c{c}}on, Mathieu and Pokutta, Sebastian}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS)}, year = {2021}, }
2020
- Locally Accelerated Conditional GradientsJelena Diakonikolas, Alejandro Carderera, and Sebastian PokuttaIn International Conference on Artificial Intelligence and Statistics (AISTATS), 2020
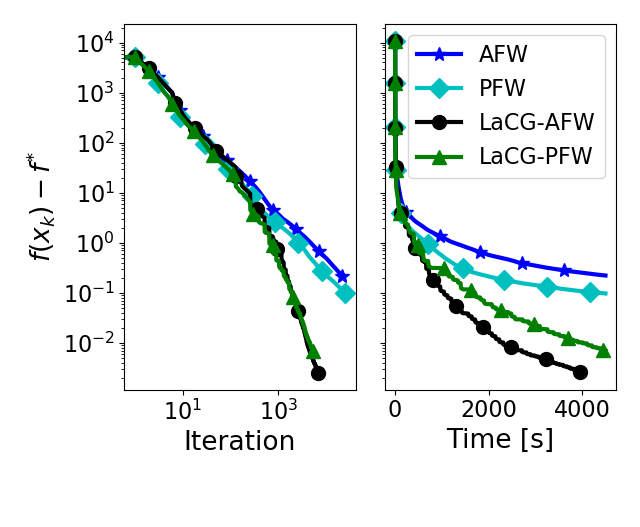
Conditional gradients constitute a class of projection-free first-order algorithms for smooth convex optimization. As such, they are frequently used in solving smooth convex optimization problems over polytopes, for which the computational cost of orthogonal projections would be prohibitive. However, they do not enjoy the optimal convergence rates achieved by projection-based accelerated methods; moreover, achieving such globally-accelerated rates is information-theoretically impossible for these methods. To address this issue, we present Locally Accelerated Conditional Gradients – an algorithmic framework that couples accelerated steps with conditional gradient steps to achieve local acceleration on smooth strongly convex problems. Our approach does not require projections onto the feasible set, but only on (typically low-dimensional) simplices, thus keeping the computational cost of projections at bay. Further, it achieves the optimal accelerated local convergence. Our theoretical results are supported by numerical experiments, which demonstrate significant speedups of our framework over state of the art methods in both per-iteration progress and wall-clock time.
@inproceedings{diakonikolas2020lacg, title = {Locally Accelerated Conditional Gradients}, author = {Diakonikolas, Jelena and Carderera, Alejandro and Pokutta, Sebastian}, booktitle = {International Conference on Artificial Intelligence and Statistics (AISTATS)}, year = {2020}, } - Second-order Conditional Gradient SlidingAlejandro Carderera and Sebastian PokuttaIn Fields Institute Communications Series on Data Science and Optimization, 2020
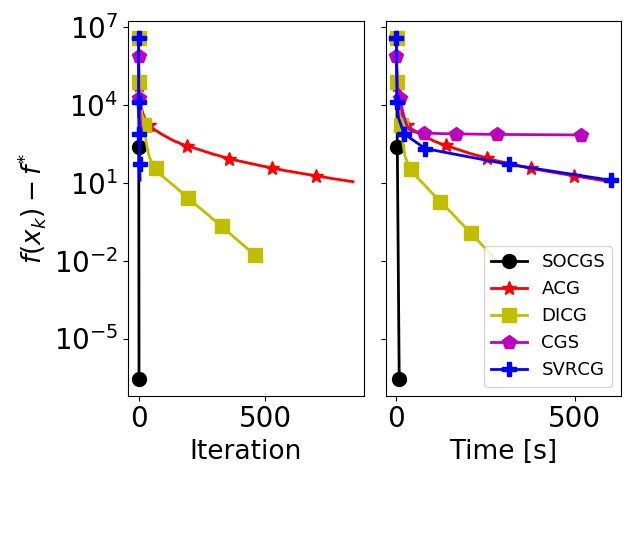
Constrained second-order convex optimization algorithms are the method of choice when a high accuracy solution to a problem is needed, due to their local quadratic convergence. These algorithms require the solution of a constrained quadratic subproblem at every iteration. We present the Second-Order Conditional Gradient Sliding (SOCGS) algorithm, which uses a projection-free algorithm to solve the constrained quadratic subproblems inexactly. When the feasible region is a polytope the algorithm converges quadratically in primal gap after a finite number of linearly convergent iterations. Once in the quadratic regime the SOCGS algorithm requires O(log(log 1/ε)) first-order and Hessian oracle calls and O(log(1/ε) log(log 1/ε)) linear minimization oracle calls to achieve an ε-optimal solution.
@incollection{carderera2020socgs, title = {Second-order Conditional Gradient Sliding}, author = {Carderera, Alejandro and Pokutta, Sebastian}, booktitle = {Fields Institute Communications Series on Data Science and Optimization}, year = {2020}, }
2019
- Breaking the Curse of Dimensionality (Locally) to Accelerate Conditional GradientsJelena Diakonikolas, Alejandro Carderera, and Sebastian PokuttaIn OPT2019: 11th Annual Workshop on Optimization for Machine Learning, 2019
Conditional gradient methods constitute a class of first order algorithms for solving smooth convex optimization problems that are projection-free and numerically competitive. We present the Locally Accelerated Conditional Gradients algorithmic framework that relaxes the projection-freeness requirement to only require projection onto (typically low-dimensional) simplices and mixes accelerated steps with conditional gradient steps to achieve dimensionindependent local acceleration for smooth strongly convex functions. We prove that the introduced class of methods attains the asymptotically optimal convergence rate. Our theoretical results are supported by numerical experiments that demonstrate a speed-up both in wall-clock time and in per-iteration progress when compared to state-of-the-art conditional gradient variants.
@inproceedings{diakonikolas2019breaking, title = {Breaking the Curse of Dimensionality (Locally) to Accelerate Conditional Gradients}, author = {Diakonikolas, Jelena and Carderera, Alejandro and Pokutta, Sebastian}, booktitle = {OPT2019: 11th Annual Workshop on Optimization for Machine Learning}, year = {2019}, }